

ChatGPT API updates
In this post, I'll unpack OpenAI's latest upgrades to the ChatGPT API and examine their potential impact.

OpenAI just announced numerous updates to ChatGPT API. These updates are significant in many ways. In this post, I’ll briefly walk you through the announcements, and explain why they matter.
A better GPT 3.5 model
With GPT-4 API access still not broadly accessible (there is a waitlist), most applications are using GPT-3.5, which is accessible to anyone. OpenAI just announced that the most capable GPT-3.5 model accessible through the API - gpt-3.5-turbo - will be updated.

Given how GPT upgrades have continued to impress, I think we’ll rapidly see even better results from the API starting on June 27th.
16K Context for GPT-3.5
This is probably one of the most important announcement with immediate impact, so it’s worthwhile to unpack it a little bit.
One of the key strengths of large language models (LLMs) lies in their ability to extract meaning from previously unseen information. As I've illustrated in previous examples, you feed an LLM with specific data and expect it to produce relevant results. This input could originate from various sources - a project's data, a document, and the like. As regular readers will be aware, there are ways to enhance the output from the LLM. You can employ advanced prompts, such as asking the model to assume a certain role, using chain of thought prompts, or separating data from instructions. These strategies generally lead to much improved results.
There's one critical limitation in all of this: You can’t pass just any amount of data to the LLM. ChatGPT imposes a limit known as the context length. Until now, this limit was 4,096 tokens. A token is a unit of text that an LLM reads and generates, which can be as short as one character or as long as one word in English or other languages. Here’s a really nice summary by OpenAI about tokens, but for the purpose of this post, it suffices to know that a token corresponds to roughly 4 English characters.
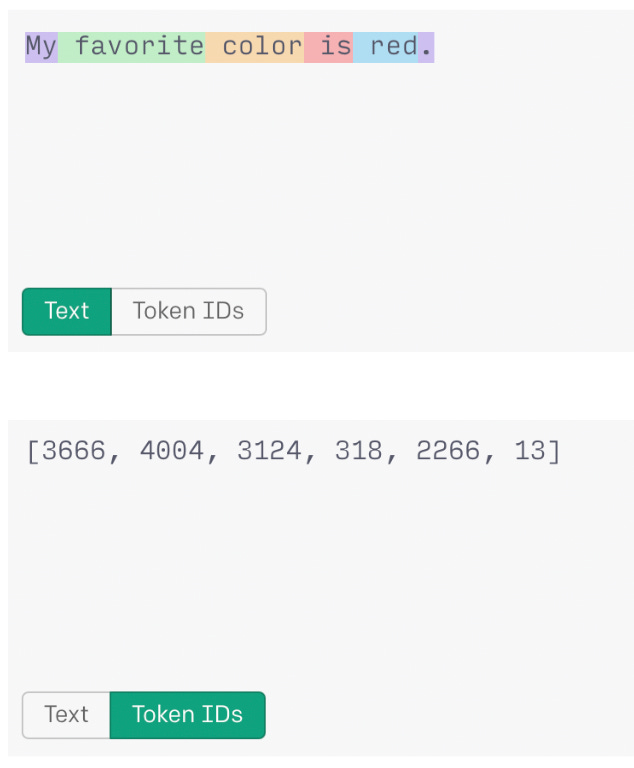
When OpenAI says that a model has a context limit of 4,096 tokens, it means that every piece of text that goes into or comes out of the model - prompts, responses, and system messages - will be counted towards that limit.
This is why the announcement of a much larger context is a big deal. There is now a GPT-3.5 model that has a context length of 16,384 tokens, which means that you can now pass much more data to the model, including longer documents, or more sophisticated prompts. 16 thousand tokens corresponds roughly to 12 thousand words, which corresponds roughly to 24 pages of text. Because the output is also counted towards the context limit, the models with longer context are also able to give you longer output, if required.

For comparison, the GPT-4 API has a maximum context limit of 32,768 tokens. The Claude model by Anthropic has a staggering context length of 100,000 tokens. But neither of these models are easily accessible, and have long waitlists.
Cost reduction
This one is straightforward: OpenAI announced a 75% cost reduction on the models, and a 25% cost reduction on input tokens for gpt-3.5-turbo. This translates into the following current cost structure:
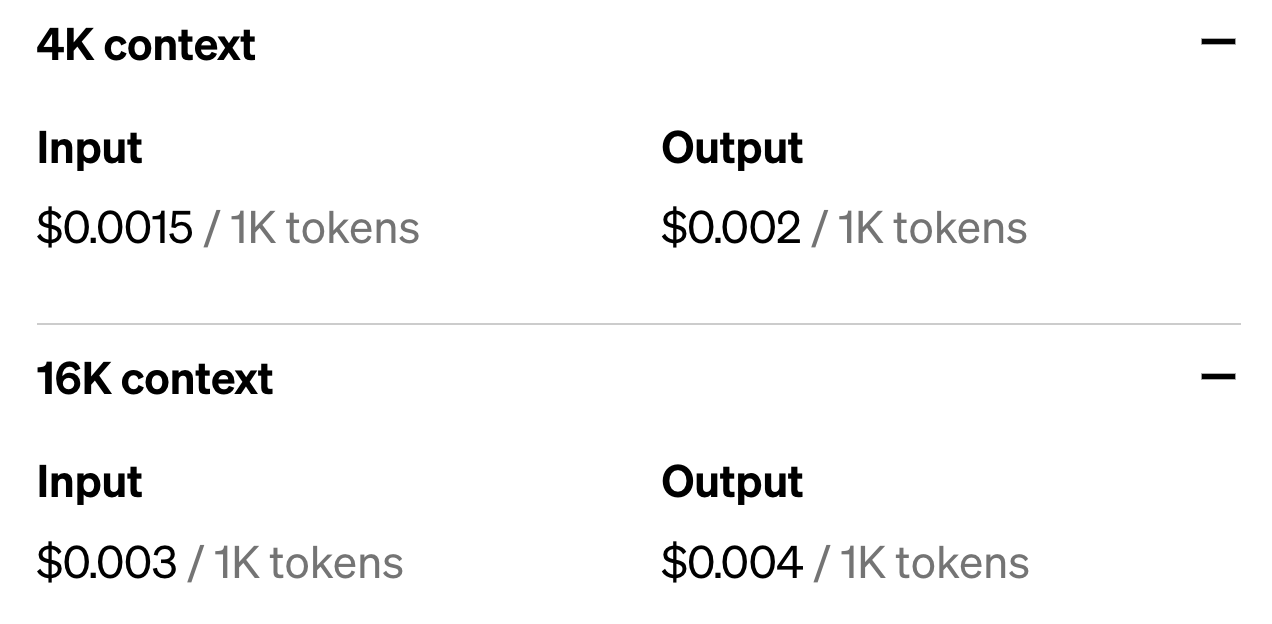
This is a significant cost reduction - not much to add here. The only downside is that you now have to consider input and output tokens separately, which complicates cost calculations a little bit. But overall, this announcement makes pretty much everyone happy.
Functions
In many ways, this might be the biggest announcement among all. However, while the other announcements - better models, larger context, lower price - are immediately useful, functions are a way to bring your LLM applications to the next level - but you’ll have to put some work into it.
In the recent post on LangChain, I discussed the power of LLM-based applications, and frameworks like LangChain are a key piece in building these applications. With functions, OpenAI is expanding in this space by offering a way for the model to intelligently:
make API calls
write emails
query databases
etc.
Functions will be quite powerful, and I will dedicate a separate post to them soon.
CODA
This is a newsletter with two subscription types. You can learn why here.
To stay in touch, here are other ways to find me:
Writing: I write another Substack on digital developments in health, called Digital Epidemiology.