

We’re all familiar with ChatGPT - an application built on the GPT model, a large language model trained on vast amounts of text. At its core, its primary skill is predicting the next token - a word, or part of a word - based on a given sequence of input. By producing a continuous stream of these tokens, the model generates text. That’s why we call it generative AI.
Generating text one word at a time isn’t inherently difficult. The real challenge is doing it in a way that not only makes sense, but also forms an appropriate response to the input. And that, of course, is anything but trivial. It requires the model to consider not just individual words, but their relationships - even when those words are far apart. The model also needs to grasp how words generally relate to one another. This is what made the “transformer” architecture - the T in GPT - so powerful. It changed the world of text generation forever.
The language of life
Now imagine applying this same revolutionary technology to another language - perhaps the most important one of all: the language of life itself. DNA is composed of nucleotides (A, C, G, T), which pair up (A with T, and G with C) forming the familiar double-helix structure. These nucleotides form genes and regulatory sequences, packaged into chromosomes, which collectively form the genome. Every species on Earth has its unique genomic sequence - and in fact, each individual has a unique sequence too. But our differences within a species are small compared to the differences between species.
For example, my genome consists of roughly 3 billion base pairs. If you compared it to the genome of a randomly chosen human on the planet, you’d find a difference of about 3 million base pairs - that’s just 0.1%. Compare my genome to that of a chimpanzee, our closest relative, and the difference jumps to around 30 million base pairs, or about 1%. Overall, that might seem small - if two books differed by only 1%, we’d probably consider it plagiarism - but these minor changes account for all the remarkable genetic diversity among humans, and even separate us from other species. In recent years, scientists have sequenced thousands of species. We’re understanding our genetic diversity better and better. But we’re still only scratching the surface of this language.
Evo 2: ChatGPT for DNA
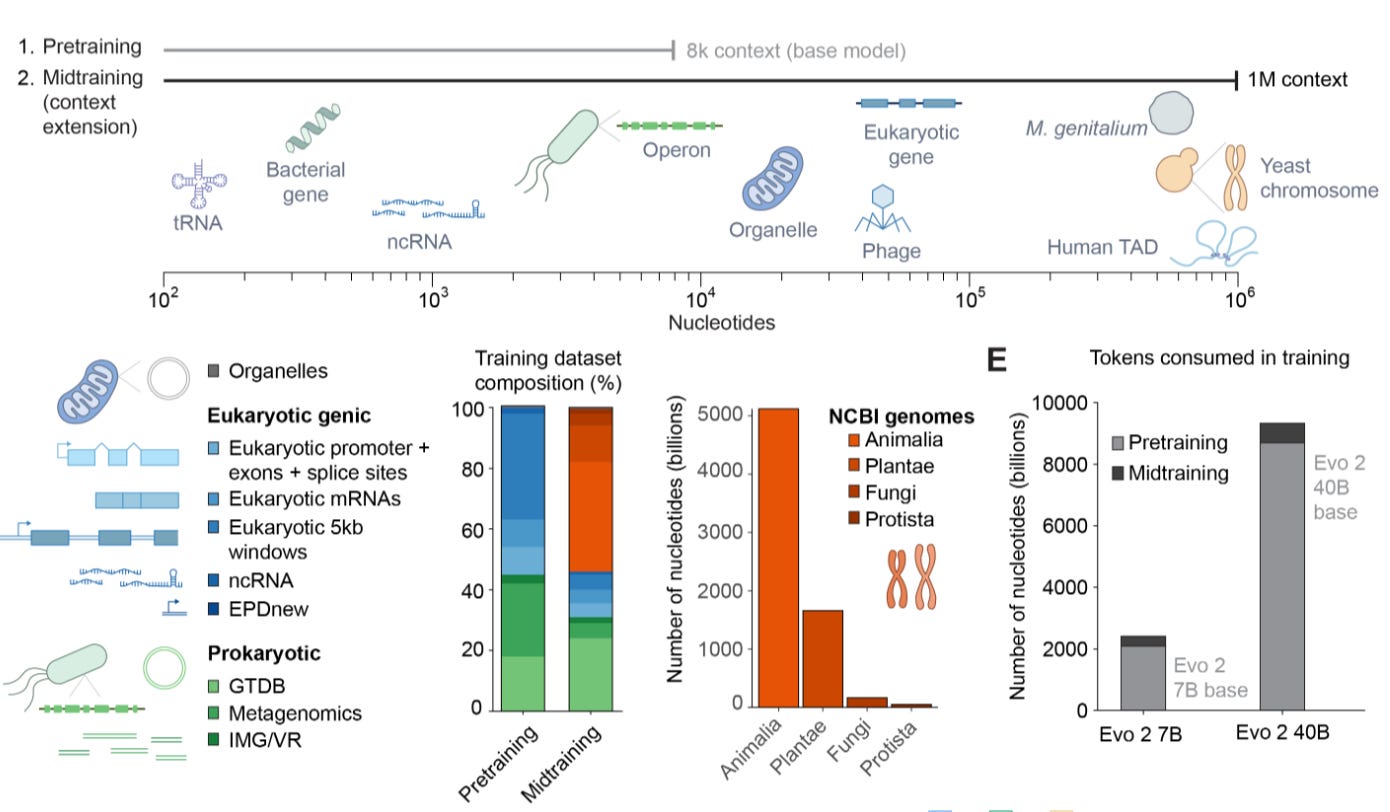
This vision of a ChatGPT for DNA has become reality with the Evo 2 model from the Arc Institute. Released just a month ago, this model is a remarkable feat of engineering. It was trained on 9.3 trillion DNA base pairs, drawn from a curated genomic atlas spanning all domains of life. For comparison, GPT-4 is estimated to have been trained on around 6.5 trillion tokens (though OpenAI hasn’t released exact figures). Meta’s LLaMA 3 and DeepSeek V3 were both trained on roughly 15 trillion tokens. So in terms of training size, Evo 2 stands alongside the leading language models.
So what can Evo 2 do? One of its key capabilities is predicting the effects of mutations. Take any one of your genes: most genes contain instructions that your cells use to build proteins, the fundamental building blocks of life. (How these proteins fold into functional structures is another challenging prediction task, famously tackled by DeepMind’s AlphaFold.) Now, if you change that sequence, how does the outcome change? Some variants are catastrophic, others are harmful, many are neutral, and a rare few are even beneficial. The challenge is figuring out which is which.
This is where Evo 2 shines. In a range of variant prediction tasks, it matches or outperforms existing baselines from other, highly specialized models. In other words, it can predict which mutations are likely pathogenic, or which variants of well-known cancer genes (like BRCA1, linked to breast cancer) are clinically important. Remarkably, Evo 2 wasn’t even trained on human variant data - only on the standard human reference genome. Yet it can still infer which mutations are harmful in humans, because it seems to have learned the evolutionary constraints on genomic sequences. It understands what “normal” DNA looks like across species and contexts.

From understanding to creating biology
What makes Evo 2 remarkable is its ability to tell when a DNA sequence feels "off," even if it hasn't seen that specific sequence before - just like how ChatGPT knows what natural English sounds like. But it gets even better: Evo 2 has learned biological features directly from raw training data - things like mobile genetic elements, regulatory motifs, protein secondary structure, and more. This is remarkable, because it goes beyond just reading DNA sequences; it captures higher-order structural information, even though that information wasn’t part of the training data. Once again, a ChatGPT comparison helps. ChatGPT can complete a sentence with proper grammar, even if it was never explicitly taught grammar rules. Similarly, Evo 2 can complete a segment of a genome with valid biological structure, even if it was never told what a gene or a protein is.
Finally, just as GPT models can generate new content - hence the name “generative AI” - Evo 2 can generate new DNA sequences. Here, we move from understanding biology to creating it. Evo 2 has been used to generate mitochondrial genomes, bacterial genomes, and parts of yeast genomes. This could be extremely useful in synthetic biology, enabling the design of organisms for biomanufacturing, carbon capture, or drug synthesis. However, like ChatGPT, Evo 2 also has major limitations: generating biologically plausible DNA sequences doesn’t guarantee these sequences are biologically functional without experimental validation. Generating DNA still appears to be a relatively limited aspect of Evo 2. But if you consider how language models evolved from GPT-3 to o3 or to DeepSeek in just a few years, it’s easy to imagine what might be in store for generative biology.

If all of that weren’t enough: Evo 2 is an open-source, open-weight model. You can download the model parameters, pretraining code, inference code, and the full dataset it was trained on.
And consider the speed: Evo 1 was released just a few months ago, in November 2024. It was already a remarkable achievement. But it was trained on only prokaryotic genomes, with around 300 billion tokens, and had a context window of 131,000 base pairs, and comparatively limited functionality. Now, just a few months later, we have a new model that scaled up the training size by a factor of 30, increased the context window eightfold, and introduced entirely new capabilities!
The rapid evolution from Evo 1 to Evo 2 mirrors the astonishingly rapid improvements we’ve witnessed in language models, which moved from frequent hallucinations to tackling complex tasks at human-level proficiency in just a few short years. Just as GPT revolutionized language generation, these DNA language models are transforming our understanding of the code of life itself.
The future of biology has never looked more exciting.
CODA
This is a newsletter with two subscription types. I highly recommend to switch to the paid version. While all content will remain free, all financial support directly funds EPFL AI Center activities.
To stay in touch, here are other ways to find me:
"Generative AI” is not called that because it generates new [novel] content - quite the opposite, actually.
The word "generative" simply describes the process of how a statistical model arrives at predictions. That is it selects ("generates") the best matching values from its training data, given the user's input (aka prompt).
In general there are discriminative and generative models.
Discriminative models find patterns in the training data, and compute the output by essentially looking up the rule that relates the output. E.g. input is an image of a cat, the model finds the "cat pattern" and outputs "cat".
Discriminative: Think "rule book" - look up the rule that applies, act accordingly.
Generative models also find patterns in the data, albeit in a different way. Instead of looking up a rule directly relating the output, it looks up the part of the training data (or rather, a statistical summary thereof) that matches the input, and then outputs the most likely next value from that. E.g. the input is "where is New York?", the model pattern-matches data containing "location" and "city" data and outputs the respective value for New York, say "USA".
Generative: Think "index in a book" - lookup the page, read what's there.