

Orca - a New Open Source LLM Champ
A new 13B "open source" model beats competitors in many benchmarks, and even approaches, or beats, ChatGPT in many areas. The most interesting part is how this was achieved.

A few days ago, Microsoft released a paper on a new open source model called Orca. This is a highly interesting development for at least three reasons:
The model outperforms other open-source models, earning the top spot among these models across many benchmarks.
Remarkably, despite having "only" 13 billion parameters, this model often achieves the performance of GPT-3.5 (the free version of ChatGPT), a model about ten times larger. In some areas, it even rivals GPT-4.
This achievement was made possible by using GPT-4’s reasoning capabilities - activated through prompts like “think step by step” - as a tutor.
But let’s take it step by step ourselves. 😉
What is Orca
Orca is a 13-billion parameter model that learns to imitate the reasoning process of models like GPT-4. It outperforms Vicuna, a previously leading open-source model, on many benchmarks, and in some cases, matches or exceeds the capabilities of ChatGPT (GPT-3.5).
Orca is set to be open-source, but isn’t quite there yet. The authors note that they “are working with our legal team to publicly release a diff of the model weights in accordance with LLaMA’s release policy to be published”. This is a fairly strong commitment, coming from Microsoft, so I fully expect this to happen, and I think we can thus treat Orca as an open-source model even now.
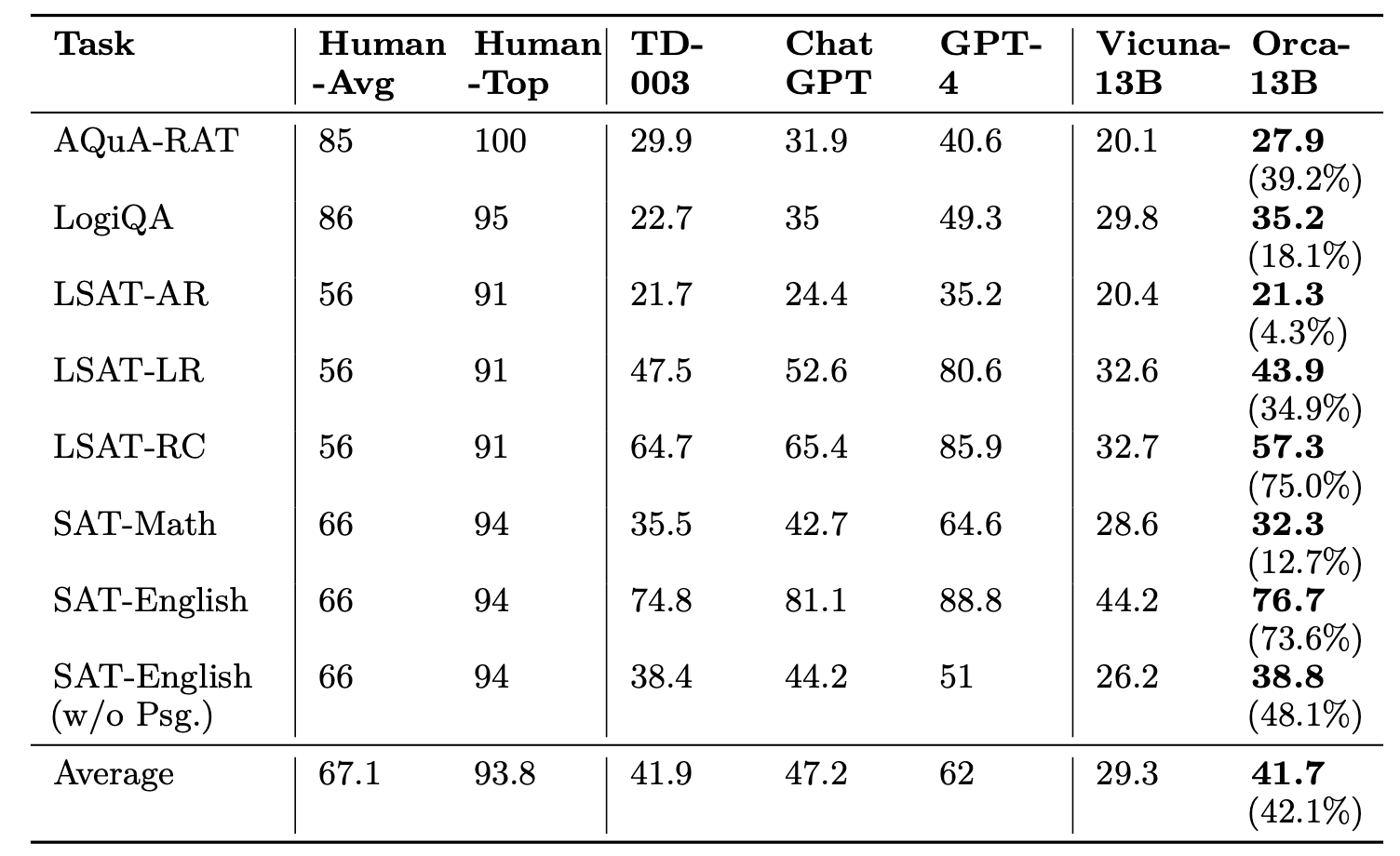
One major strength of this paper is the extensive evaluation of the model on numerous benchmarks. While I won't go into all of them, I should note that Orca's performance is extremely impressive, even occasionally surpassing GPT-4. This should be taken with a grain of salt, of course, but the overall performance enhancements over the similarly sized Vicuna model are simply remarkable.

Move over, Camelids - the age of the Oceanic dolphins has arrived.
How this was achieved
In my view, this is the most fascinating part of the paper. Essentially, the authors achieved these results by leveraging GPT-4’s reasoning capabilities - triggered by prompts such as “think step by step” or “explain it to me like I’m five” - as a tutor.
Previous open-source models have also built upon outputs from ChatGPT. However, they've primarily used pairs of questions and answers to fine-tune the model. Orca advances beyond this approach by learning not only from the answers but also from the reasoning that GPT-4 exhibits.

It's important to note that Orca's evaluations were all conducted using zero-shot standard prompts. This means that Orca directly attempted to address whatever challenge each benchmark posed. In other words, it's quite likely that the impressive performance highlighted in this paper is merely a baseline. Orca could potentially perform even better if it used other techniques, such as a chain-of-thought and others.
Takeaways
My key takeaways are twofold: First, there's a new champion in the open-source language model space, easily surpassing the previous leaders. Second, the method by which this was accomplished illustrates the potential of these models to self-improve. This suggests that we're only at the early stage of what's likely to be a rapid evolution towards increasingly high-performance models. Exciting times, indeed!
CODA
This is a newsletter with two subscription types. You can learn why here.
To stay in touch, here are other ways to find me:
Writing: I write another Substack on digital developments in health, called Digital Epidemiology.