

Three key developments
Three publications in recent weeks show the breakneck pace at which AI advances. Here's a selection of three developments that are very noteworthy.

Everybody talks about the misinformation tsunami, but quite frankly, I am struggling to not drown in information! AI is developing at incredible speed that makes it hard to keep up.
To fight information overload, you need curation. In that spirit, here’s a selection of three developments that I think you should be aware of.
MedPaLM 2: Medical LLM
What happened: On May 16, 2023, Google Research and DeepMind published a preprint entitled Towards Expert-Level Medical Question Answering with Large Language Models. The paper assessed a new model, Med-PaLM 2, demonstrating significant progress in medical question answering. Med-PaLM2 scored up to 86.5% on MedQA, a medical benchmarking dataset that contains medical questions designed to mimic the US Medical Licensing Exam (USMLE).
Perhaps most notably, in a detailed human evaluation, doctors favored Med-PaLM 2's responses to 1066 medical questions over those given by other doctors on eight out of nine criteria related to clinical usefulness.
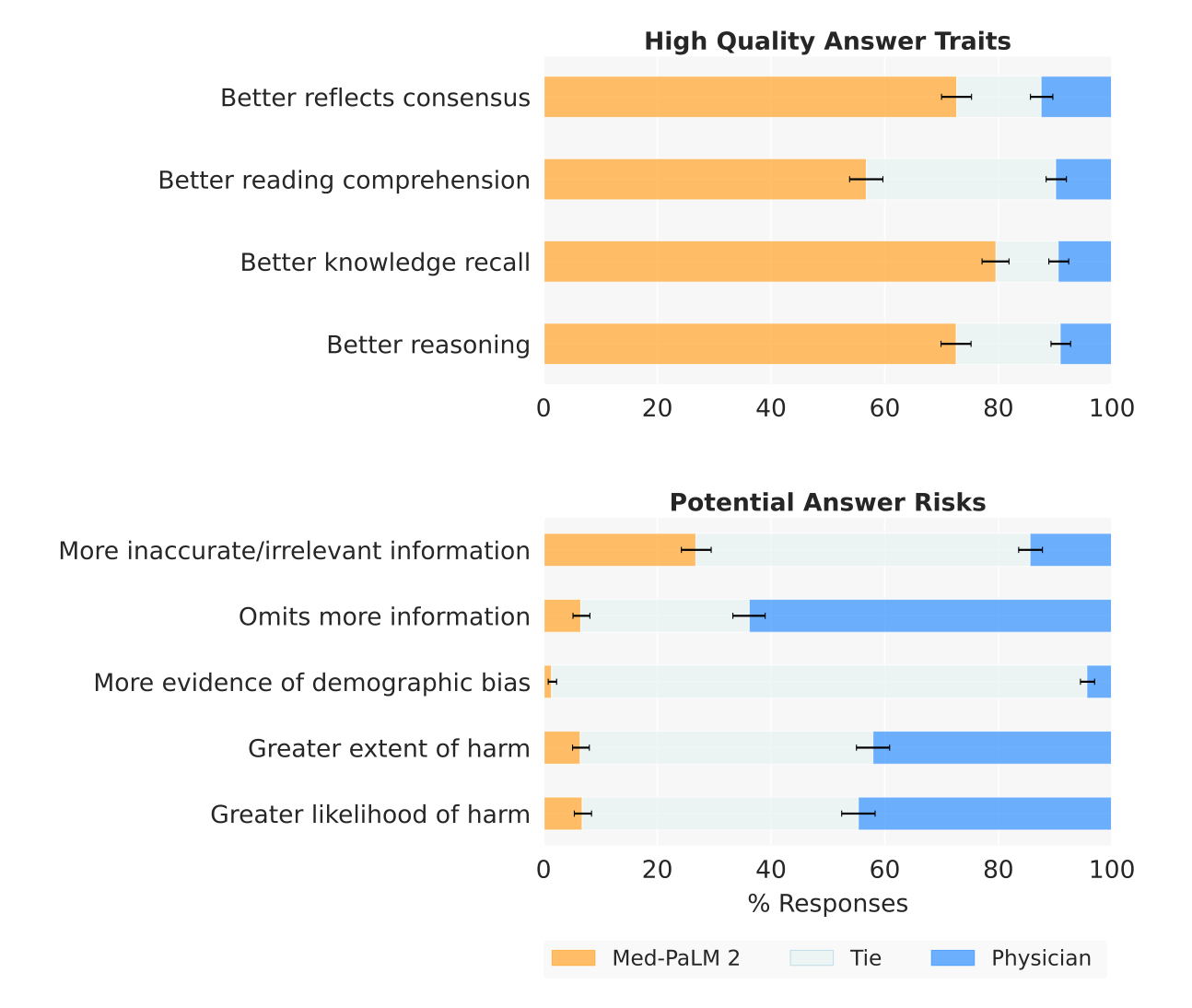
They also showed a comparison with other models, but I think the figure could use some improvements for better clarity. Notably, GPT-4 was not included in their comparison. So, I've reproduced and amended it to show the massive jumps in recent months:
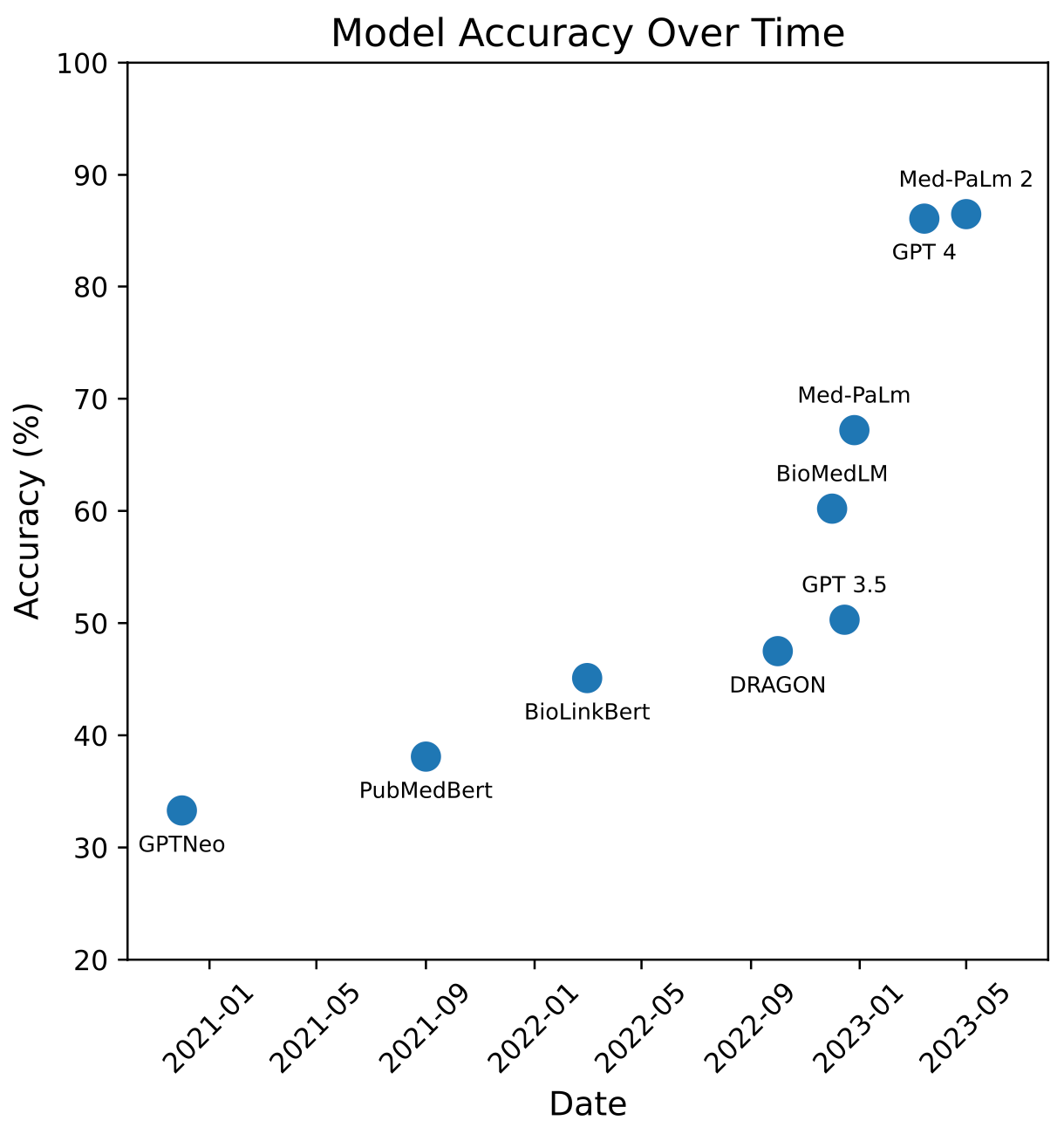
Why it matters: The health LLM space is advancing rapidly. LLMs can now pass medical exams with flying colors, and the evidence is getting stronger that people - even doctors - prefer the model’s response to those given by doctors. We're in for a major overhaul of the medical system.
ImageBind: More than just images and text
What happened: On May 9, Meta published a paper ominously entitled ImageBind: One Embedding Space To Bind Them All. ImageBind is a new approach that creates a powerful connection between six different types of data (modalities), including images, text, and audio. It notably also includes depth information, which is essential for 3D rendering, an area Meta was leading with their Metaverse push.
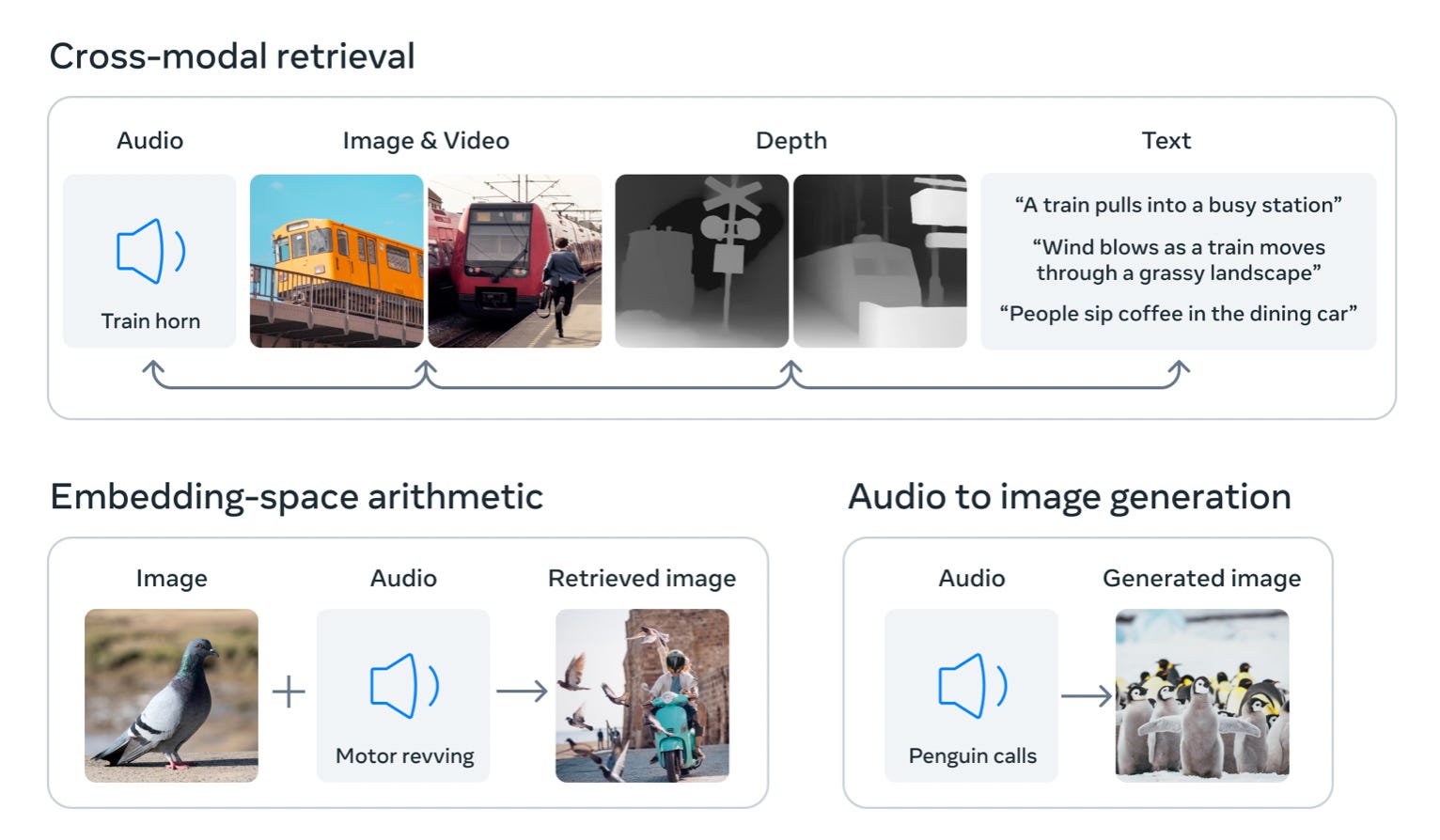
Why it matters: Using images as a common basis, this technology - which is not a generative model - allows other generative models to seamlessly link different modalities. This will allow them to connect modalities, such as text to images (like Dall-E or MidJourney), but also novel ones, such as text to audio, audio to image, etc. As the illustration above indicates, the capabilities that are opening up here are endlessly fascinating.
Fine-tuning with 1000 prompts
What happened: On May 18, academic researchers and Meta published a paper entitled LIMA: Less Is More for Alignment. LIMA is a 65B parameter LLaMa language model, fine-tuned with only 1,000 carefully curated prompts and responses - and without any reinforcement learning. Remarkably, it performs extremely well: responses from LIMA are either equivalent or preferred to GPT-4 in 43% of cases.
Why it matters: While we should avoid over-interpreting, this development appears to be a significant step towards what we understand as intelligence. The base model, LLaMa, provides the backdrop (“the brain”), and the fine-tuning with merely 1,000 prompts represents individual learning. Considering that LLaMa's performance alone isn't particularly impressive, this paper dramatically demonstrates the importance of just a few prompts. And all of this has been achieved without any human feedback...