

Training, Reasoning, Coordination: The Three Levers of AI Progress
How to Think About AI Progress

Before we start: The AMLD Intelligence Summit is coming up at EPFL on Feb 10-12, 2026. Tickets are available now at www.appliedMLdays.org!
Also, my book on AI is now out in French (IA: Comment ne pas perdre le nord) and in German (Kompass Künstliche Intelligenz - this version has made into the Swiss Beststeller list - currently at #5 🤩). I’m working on the English translation which I hope to release early next year.
How to Think About AI Progress
There’s a simple mental model I use when people ask me where AI is heading. It doesn’t predict AGI timelines or make grand claims about intelligence. It just answers a practical question: what are people actually turning up to get the next jump in capability?
The answer keeps changing, and understanding why it changes is more useful than memorizing which technique or model is hot this month.
AI progress comes from three levers:
Training: Make the model bigger, feed it more data, train it longer
Reasoning: Let it think more at inference time
Coordination: Have multiple models and tools work together
I think of these are three overlapping S-curves. Each lever delivers great returns until it doesn’t, at which point the marginal gains shift to the next lever.
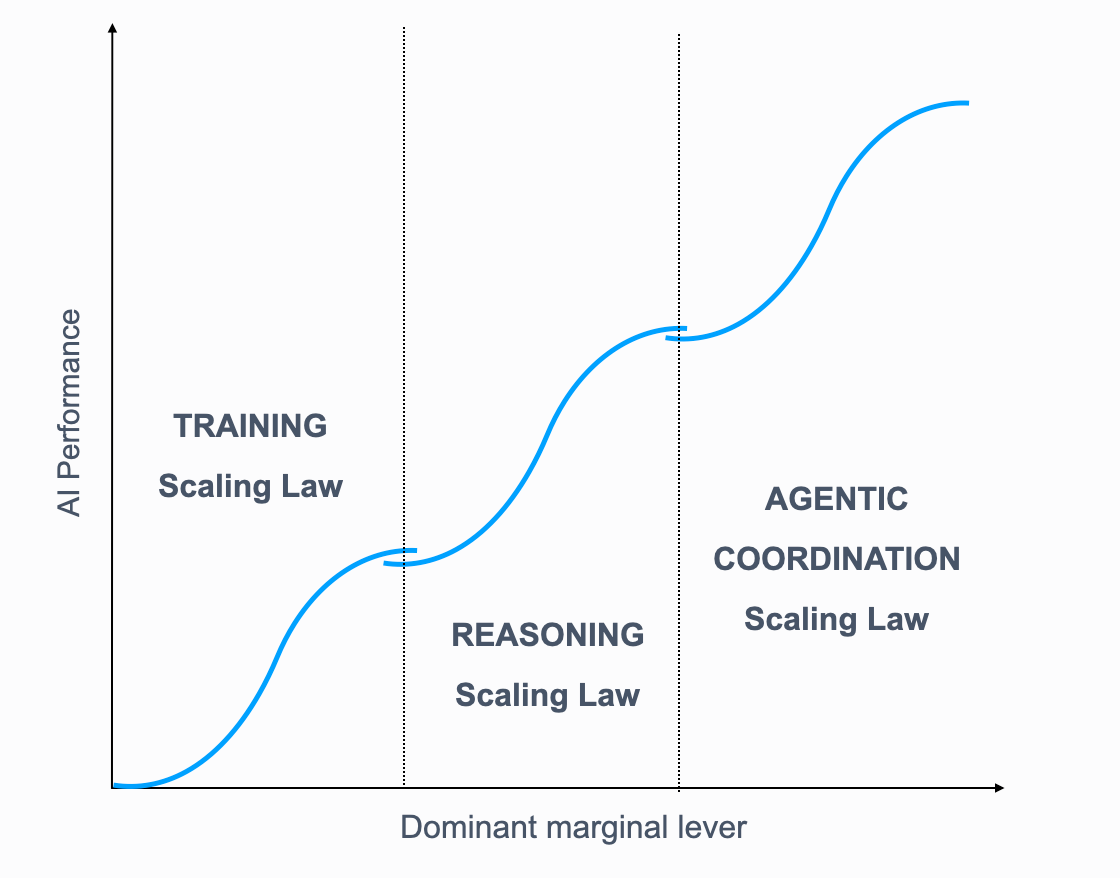
Training: The Lever That Built the Industry
For years, the recipe was simple: more data, more compute, bigger models. The results were spectacular. GPT-2 to GPT-3 to GPT-4 showed that each jump came primarily from scaling up. The scaling laws papers from OpenAI and DeepMind gave this an empirical foundation: performance improves predictably with scale.
What changed is that we’re now hitting real constraints. The clearest signal came from GPT-4.5, released in February 2025. By all accounts, it was OpenAI’s largest model ever, estimated at roughly 10x the compute of GPT-4, with training so intensive it had to be spread across multiple data centers. The API pricing reflected this: $75 per million input tokens, about 15-30x more expensive than GPT-4o. And yet the results were... modest. GPT-4.5 showed improved language fluency and reduced hallucinations, but it didn’t crush benchmarks, lagging behind even the smaller o3-mini on reasoning tasks. OpenAI’s own system card initially stated it was “not a frontier model.” They also announced it would be their last model without built-in reasoning capabilities. Ilya Sutskever put the situation bluntly at NeurIPS 2024: “Pre-training as we know it will unquestionably end. We’ve achieved peak data. There’s only one internet.”
This isn’t controversial anymore, I think. Training scaling isn’t dead, but it’s no longer the dominant lever.
Reasoning: The Lever That’s Working Now
In September 2024, OpenAI released o1 and demonstrated something truly new. The model scored in the 89th percentile on competitive programming, placed in the top 500 for the US Math Olympiad qualifier, and exceeded PhD-level accuracy on physics, biology, and chemistry benchmarks. These gains didn’t come from a bigger model. Instead, they came from a model trained to reason, to use more compute at inference time.
The key chart from the o1 paper shows a log-linear relationship between test-time compute (i.e. inference) and accuracy. Spend more compute when answering, get better answers. This is a new scaling law, distinct from training scaling.
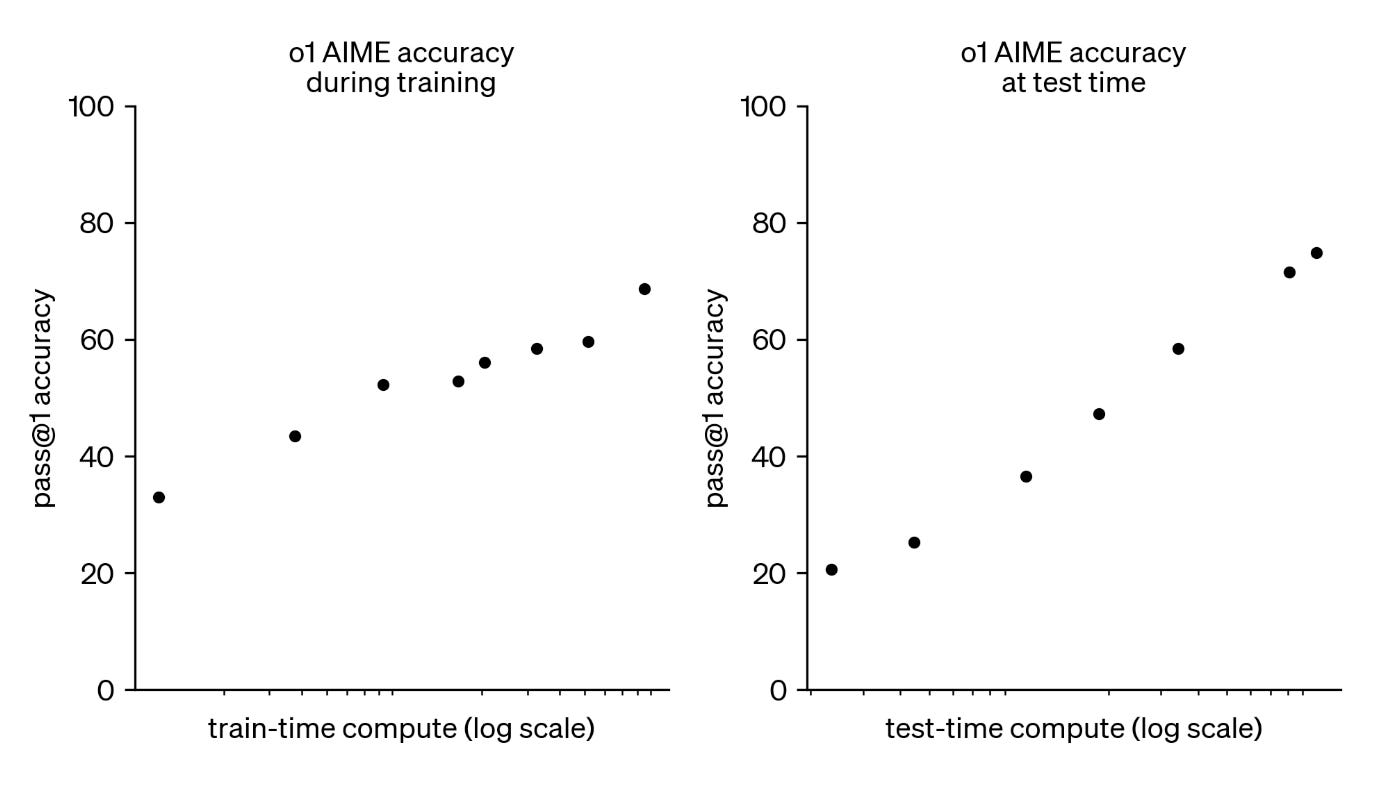
The evidence has only strengthened since then. Yesterday, OpenAI released GPT-5.2 with three explicit modes: Instant for quick answers, Thinking for complex reasoning, and Pro for maximum accuracy. Other model providers do similar things. The entire product architecture now reflects the test-time compute paradigm.
Just look at this graph about model performance to see what reasoning has done:
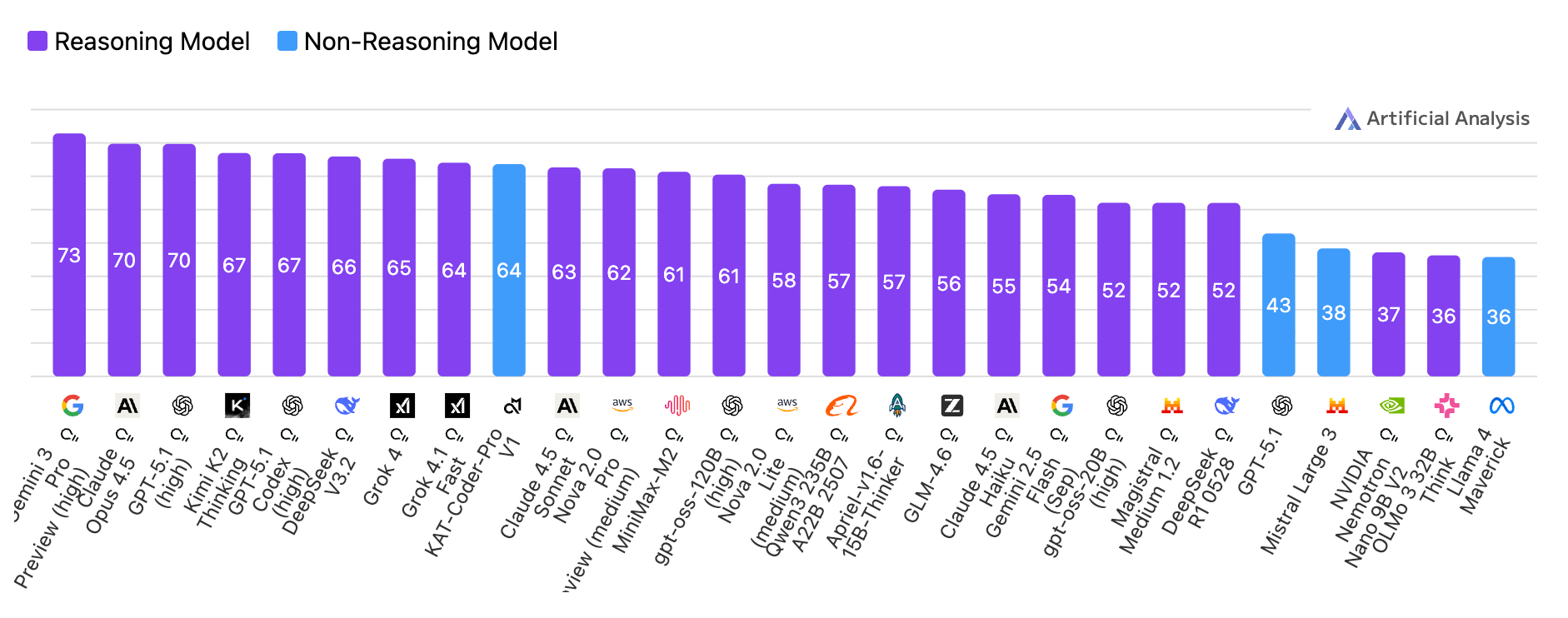
But the more interesting development came last week from DeepSeek. Their V3.2 paper addresses a question that had been lingering: we knew reasoning helped, but how do you scale it further? Their answer was a “stable and scalable RL protocol” for post-training that allowed them to push compute into the reasoning lever at a scale that wasn’t previously feasible. They allocated over 10% of their pre-training budget to post-training RL alone. The result was that their high-compute variant, DeepSeek-V3.2-Speciale, achieved gold-medal performance on both the 2025 International Mathematical Olympiad and the International Olympiad in Informatics, matching Gemini-3.0-Pro and surpassing GPT-5.
This matters because it suggests the reasoning S-curve still has room to run. The lever isn’t exhausted; we just needed better methods to keep pushing it.
So, reasoning scaling is the dominant lever right now. That’s measurable across every major benchmark.
Coordination: The Lever That Might Be Next
Now we get speculative.
The pitch for “agentic” AI is intuitive: break big tasks into smaller ones, have specialized agents handle each piece, let them use tools and check each other’s work. Researcher, writer, editor, fact-checker. Division of labor, basically.
The problem is that the evidence for this remains thin compared to the first two levers. Agentic systems are hard to build, and many initially promising attempts eventually fail to scale. That said, the picture is clearly shifting. OpenAI’s GPT-5.2 announcement yesterday talks about “more reliable agentic workflows” and positions the model for “complex, multi-step projects.” DeepSeek’s V3.2 paper describes synthesizing over 1,800 environments and 85,000 complex prompts specifically to train tool-use alongside reasoning. The framing tells you where the industry thinks the next lever is. But the empirical confirmation we had for training scaling in 2020 or reasoning scaling in 2024 isn’t quite there yet for coordination.
There’s a reason to take this bet seriously despite the thin evidence from benchmarks. Consider that human brains haven’t changed much in the past 10,000 years. The neural hardware running in your head is essentially the same hardware that ran in the heads of hunter-gatherers on the savanna. And yet here we are, splitting atoms, sequencing genomes, landing on the moon. The difference isn’t individual intelligence. The difference is that those brains learned to coordinate: through language, writing, institutions, specialization, and the accumulation of knowledge across generations. Coordination is how you get civilization-scale capability out of roughly constant individual capability. If that pattern holds for AI, the third lever could matter enormously even if individual model intelligence eventually starts to plateau.
So when I show the graph with three S-curves, I want to be honest about it: the first two are backed by solid data. The third is a bet, but it’s a bet with historical precedent.
Why This Matters
There’s a pattern here that echoes Rich Sutton’s “bitter lesson”: general methods that scale with compute tend to win over clever algorithmic tricks. The first two levers confirm this. Once you have the transformer architecture, throwing more compute at training delivers. Once you have RL on chain-of-thought, throwing more compute at reasoning delivers.
Each new lever required an algorithmic breakthrough to unlock it in the first place. Transformers enabled training scaling. Reinforcement learning on reasoning traces enabled test-time (inference) scaling. The insight comes first, then the compute takes over.
Ilya Sutskever put this well in his recent conversation with Dwarkesh Patel. He described 2012-2020 as “the age of research,” 2020-2025 as “the age of scaling,” and what comes next as “back to the age of research again, just with big computers.” Scaling alone won’t transform capabilities anymore (though the DeepSeek paper suggests we still have some way to go). We need new ideas to unlock the next axis for compute to pour into. And we don’t yet know what insight, if any, will make coordination scale the way training and reasoning have.
The history suggests that when someone finds it, compute will do the rest.
CODA
This is a newsletter with two subscription types. I highly recommend to switch to the paid version. While all content will remain free, all financial support directly funds EPFL AI Center-related activities.
To stay in touch, here are other ways to find me:
Excellent breakdown of the shifting levers. What really stands out is how DeepSeek's stable RL protocol for reasoning shows we're not done squeezing that second lever yet. I've been seeing similar pattrns in production, where increasing test-time compute consistently beats throwing more training params at the problem. But here's what I'm curious about: coordination might actualy need a fundamentally differnt infrastructure since current systems aren't built for multi-agent memory or contextsharing.
Very interesting Marcel. Thank you for making this content accessible for us, non tech people!