

Weekend Read in AI - #3
The week a Chinese open AI model shook the markets. Plus AI insights from Google’s 8th employee, Urs Hölzle.

Dear readers,
This past week might have been the most chaotic in AI history - ever. A Chinese company unveiled a new reasoning model, DeepSeek-R1, sending both markets and geopolitics into a frenzy. You’ve likely seen various takes already, so I’ll keep this brief and focus on what I believe is a) important and b) reasonably certain.
Before getting to it, a quick reminder: AMLD 2025 (Applied Machine Learning Days) is coming up on February 11-14 at the Swiss Tech Convention Center at EPFL, Switzerland. With over 60 tracks and hands-on workshops, 300+ speakers, and a stellar keynote lineup, it’s an event you won’t want to miss. Learn more at 2025.appliedMLdays.org.
DeepSeek
So, what exactly happened? DeepSeek is a Chinese company that has been releasing open-source AI models since 2023. This is worth emphasizing: DeepSeek didn’t appear out of nowhere - it has been steadily putting out open models for over a year.
Its first series of models came out in November and December 2023, all under the MIT license, which grants full freedom in how the model - or anything built from it - can be used. In the AI world, this is a big deal. Most powerful models are closed-source, and even those that are open, like Meta’s Llama models, come with serious licensing restrictions. Despite this, DeepSeek’s early models went largely unnoticed outside the AI community.
In May 2024, DeepSeek launched a second series, starting with DeepSeek-V2, again under the MIT license. Still, few outside tech circles paid attention. Then, in December 2024, just a month ago, DeepSeek-V3 was released - matching OpenAI’s GPT-4o in performance. Yet again, hardly anyone noticed.
That changed on January 20, 2025, when DeepSeek dropped DeepSeek-R1, a reasoning model built on DeepSeek-V3. This time, the media took note. Within days, news articles appeared, mostly fixating on two aspects: that the latest DeepSeek models were from China, and that they seemed to have been trained with dramatically fewer resources - i.e. fewer GPU hours - than their US counterparts. The story quickly gained momentum, and on Monday, January 27, the stock market reacted. Nvidia’s market cap plunged by $600 billion, though some of those losses have since been reversed.
The reaction came from two converging concerns, leading some to call this AI’s “Sputnik moment.” First, there was the geopolitical angle: a Chinese company, seemingly operating under strict US-imposed compute restrictions, had managed to build a model that rivaled the best from OpenAI and Google. Had China already taken the lead in AI? The second was the economic angle: if DeepSeek-R1 really was as powerful as other leading models but required just 5% of the compute power, that could mean the market was overvaluing AI compute providers, particularly Nvidia.
What got less attention (but was arguably more interesting IMO) was the fact that DeepSeek-R1 is a reasoning model. These models generate responses by taking more time to “think” through problems, producing better answers. The leading AI producers, from OpenAI with its o1 (and soon o3) to Google with Gemini-2-Thinking, are all moving in this direction. But what makes DeepSeek-R1 stand out is that, unlike other reasoning models, it actually discloses its thinking steps. This transparency offers an entirely new way to understand how these models work.
The second overlooked aspect was that DeepSeek-R1 was not only MIT licensed, but also was fully open-sourced, with the exception of the training data. Alongside the model, DeepSeek released a relatively detailed research paper explaining its architecture. That means anyone can replicate, modify, and build on it, and even start businesses - legally, thanks to the MIT license. And in fact, many aspects of DeepSeek-R1 have already been reproduced. The story checks out.
What it means
In my view, the key consequences are as follows:
China is now publicly recognized as a leader in AI. This isn’t exactly new: China’s AI progress has been well-documented. But until now, the public at large hadn’t taken notice. That has changed.
The model was almost certainly trained with far less compute, which is a major development. AIs that require less energy are better for everyone. That said, I don’t believe compute constraints are going away anytime soon, for three reasons. First, top models will keep growing in size - they’re large because they capture more insights from more data, and as more data becomes available (including synthetic data), models will continue expanding. Second, greater efficiency drives greater demand - more accessible AI means more people will use it, offsetting efficiency gains. And third, reasoning models are extremely compute-intensive at runtime. Since they take longer to “think” through problems, they consume significantly more resources per query.
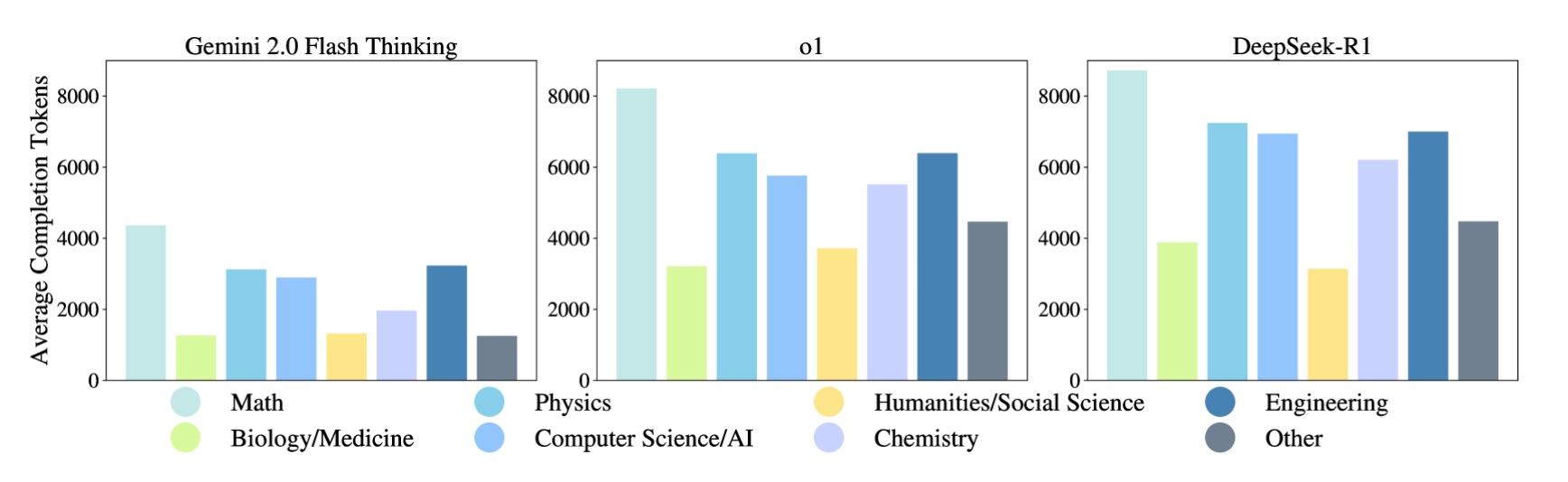
A good example of this is when leading standard and reasoning models were tested on the notoriously difficult “Humanity’s Last Exam”. Reasoning models used about 10 times more tokens - and, by extension, substantially more compute - than standard models: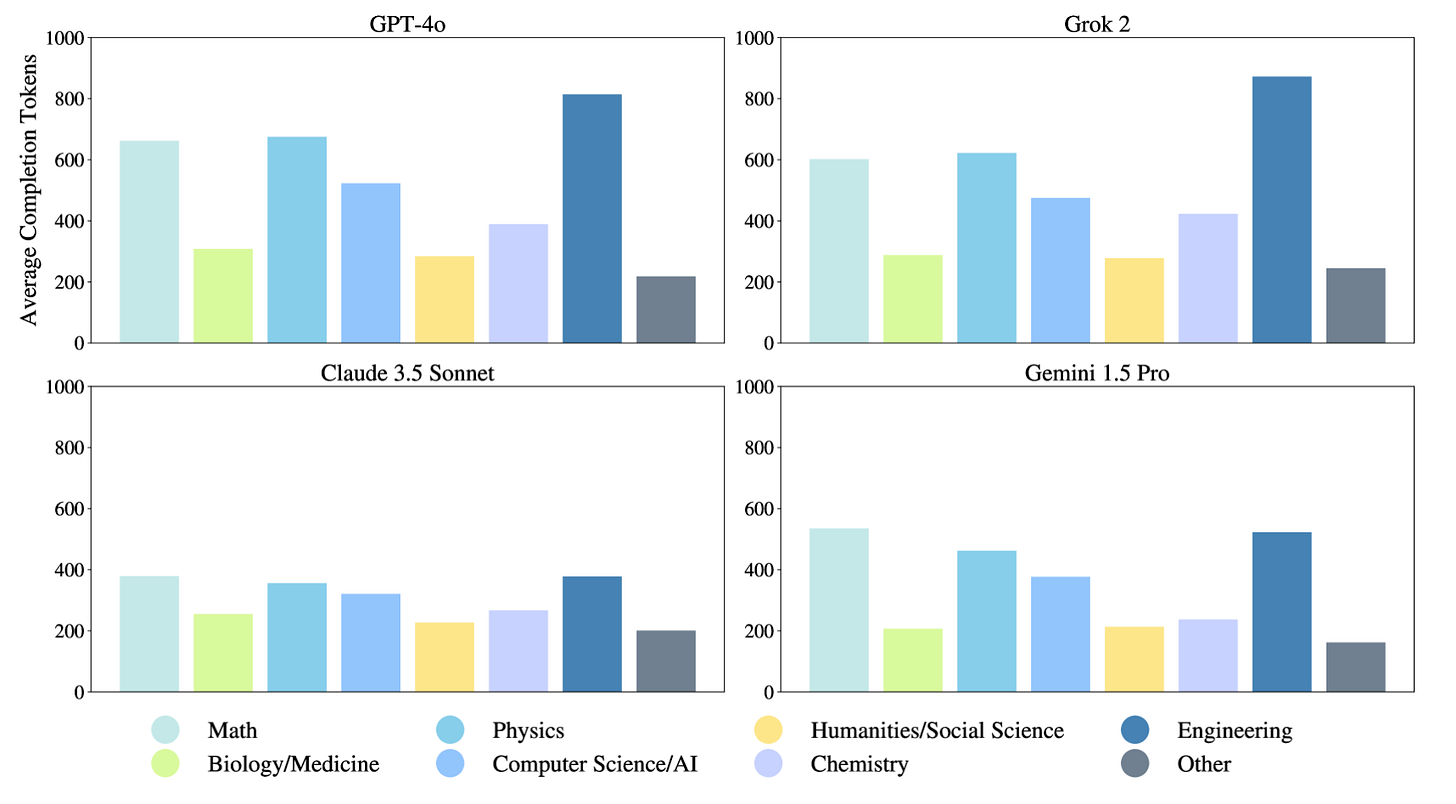
Tokens used by standard, non-reasoning models. Source: https://arxiv.org/html/2501.14249v1 
Tokens used by reasoning models. Source: https://arxiv.org/html/2501.14249v1 The transparency of DeepSeek-R1, combined with its permissive license, is about to trigger a Cambrian explosion of new AI models built on its foundations, or at least inspired by its core ideas. As a huge fan of open AI models, I see this as great news.
The timeline to human-level AI has accelerated. Reasoning models should, in principle, help us develop even more advanced reasoning models. On top of that, they may have unlocked a path to rapid performance gains through reinforcement learning - a topic I’ll explore more in detail in a future post.
Perhaps it’s also worth noting what it does NOT mean:
First, compute constraints are not going away - far from it. Usage of these models is about to skyrocket, and they remain compute-intensive to run. More broadly, we are living in the age of AI and information, where compute is the core limiting factor. It’s hard to see how that would change.
Second, this does not mean future AI models will all ignore what happened in Tiananmen Square in 1989. While the original DeepSeek-R1 has been trained to remain silent on topics the CCP prefers to avoid, its breakthroughs can, and will, be incorporated into other models with no such restrictions. There’s no reason to assume that all future models built on these advancements will share its limitations.
Podcast episode “Inside AI” with Urs Hölzle
I recently had the chance to speak with Urs Hölzle - Google’s 8th employee, former SVP of Technical Infrastructure, and fellow Swiss - for a podcast episode of “Inside AI,” the AI podcast from the EPFL AI Center (Link to episode on Apple Podcasts, Spotify)
While the audio quality could use some improvement, I highly recommend giving the ~1-hour conversation a listen. We cover a wide range of topics, including AI’s energy challenges, its economic outlook, and what a European response to AI could look like.
To whet your appetite, here are a few quotes from the episode:
1️⃣ ”Here you have a model; either 10x your revenue, or drop your cost by a factor of 10. Which one is more feasible? The second one is an engineering job; for the first one, you might have to change the world.” - on why we should expect many more efficiency breakthroughs for AI models
2️⃣ “Whenever you move actual things - air and cars and whatever - the energy intensity is much, much higher than moving electrons between the compute units of the CPU. Moving a few electrons in the CPU in order to move fewer atoms in the real world is like a 10,000:1 trade-off kind of thing. And so there's really a lot of opportunity there.” - on why all energy discussion should focus on moving atoms, not electrons.
3️⃣ “If you write the history of the first 20 years of AGI, energy will not be mentioned.” - on what the real issues with AI will be.
4️⃣ ”I absolutely agree that if progress [on AI] stopped today, you'd still see substantial impact [on the economy] in the next five or even 10 years. And that's because translating this into an application that actually works in business is huge. And that's, I think, is I feel what's misunderstood.” - on how we are just at the beginning of the AI revolution, on where the money will be made.
5️⃣ “I think Europe has a mindset problem, not a talent problem. - The first one is the focus on risks. But then the second one is that there is this implicit assumption that doing nothing is safe. And it's just completely not true.” - on how the European mindset needs to change in order to be relevant in the AI age.
There are plenty more great quotes, but I hope this gives you a sense of the breadth of topics we covered. Urs has truly fascinating insights, especially as someone who has been there from the very beginning at one of the world’s most dominant tech companies.
CODA
This is a newsletter with two subscription types. I highly recommend to switch to the paid version. While all content will remain free, I will donate all financial support to the EPFL AI Center.
To stay in touch, here are other ways to find me:
Social: I’m mainly on LinkedIn but also have presences on Mastodon, Bluesky, and X.
Podcasting: I’m hosting an AI podcast at the EPFL AI Center called “Inside AI” (Apple Podcasts, Spotify), where I have the privilege to talk to people who are much smarter than me.
Conferences: I’m an organizer of AMLD, the Applied Machine Learning Days - our next large event, AMLD 2025, takes place on Feb 11-14, 2025, in Lausanne, Switzerland.